3
Dec 2018


A data model shows the logical structure of a database, including the relationships and constraints that determine how data can be stored and accessed. The structure of a data model is largely a representation of the company’s operational business model with primary considerations for how the data is going to be used across the business.
For example, the data stored in the model may be to support high performance Business Intelligence systems, where speed and depth of data are critical. Alternatively, the data stored in the model may be to support a Single Customer View where individual customer transactions are important.
The process of designing and developing a data model allows the business and solution developers validate the requirements meet the business needs. Correctly designed data models ensure the solution is appropriately optimised, supports data integrity and positively impacts the scalability of the solution.
Data models also provide the structure for related processes to work to – for example ETL (Extract Transform Load) tools such as Talend used for ingesting source data into the solution, or Business Intelligence tools such as Tableau used for interacting with the solution and delivering insights.
It’s true that both above can exist without the presence of a developed data model, however, there are likely to be inefficiencies between the two processes and potential issues with poor quality of data etc.
There are many kinds of data model, some of which date back to the start of computing. While some of the earlier data models, such as the Hierarchical and Network model can still be found today, they are far less common than more recent versions, such as the relational model, first introduced in 1970 and the Star Schema introduced in 1996.
There are usually several factors involved when deciding on which is the most suitable model. These include the type of database management system available for the project, use case priorities such as speed and budget and the primary application for the data, for example Business Intelligence, Operations etc.
Let’s explore the Relational model and Star Schema in more detail:
The Relational model is the most commonly used model and organises data into tables (relations) consisting of columns and rows.
Each column includes an attribute such as email address, post code, forenames. Attributes are selected to form the primary key which can be referred to in other tables as foreign keys. Primary keys can be associated to single or multiple columns if they return unique values forming the primary constraint for the table. The data type for each column is also specified.
Each row in a table contains the specific data, such as a customer’s forenames, email address and postcode.
Relationships between each table are mapped specifying the type of relationship such as a one-to-one, one-to-many.
The example below containing seven tables identifies the keys in the first column, the attribute name in the second and the allocated data type in the third.
Relationships are mapped using connecting lines, each with a start and end shape indicating the relationship type.
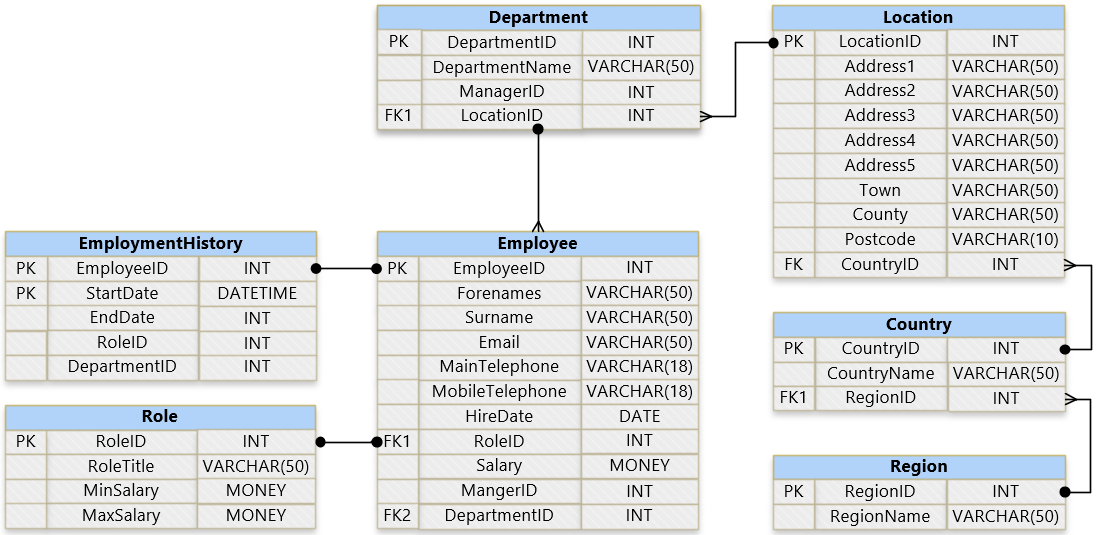
The example above shows the following relationships:
![]() one-to-one
one-to-one
![]() one-to-many
one-to-many
One of the main benefits of the relational model over the hierarchical and network alternatives is the ability to change its structure without significantly impacting the application. Altering the structure of hierarchical and network models almost always require an update to the application for it to continue to function, regardless of whether the application utilises the new object or not.
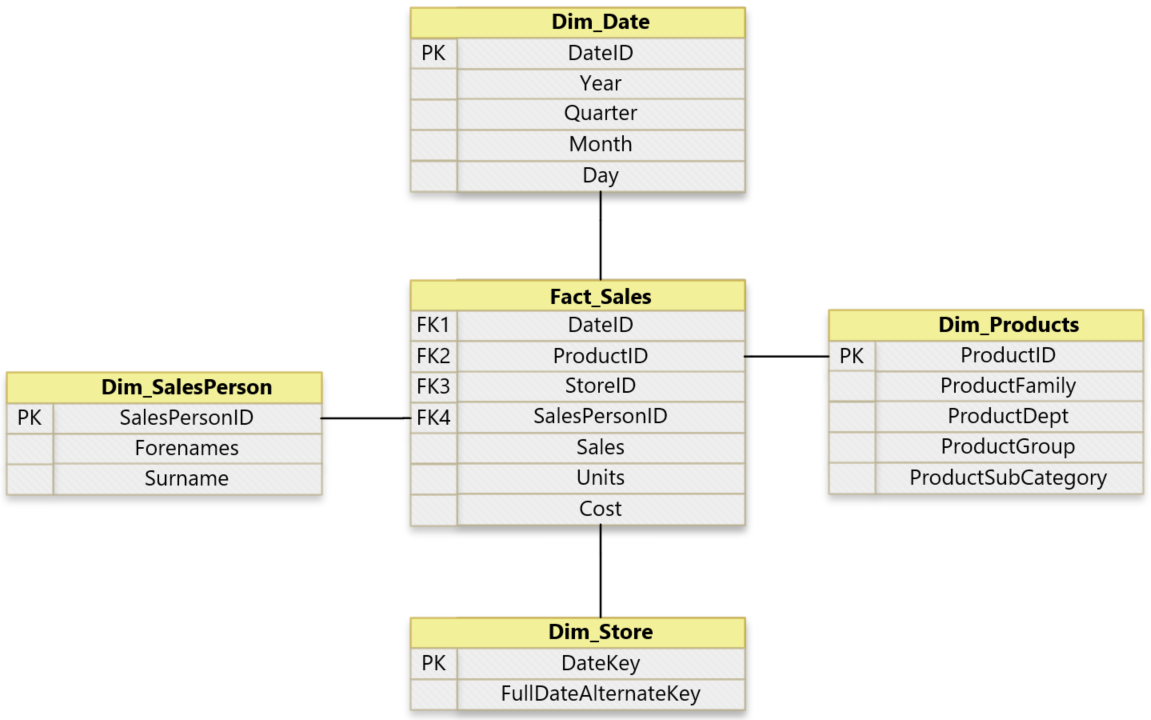
The star schema organises descriptive data into dimensions and measurable data into facts. Examples of dimension data include product description, surname and year. Examples of facts include sales, cost and units.
The primary application for the star schema is in data warehousing where the database supports reporting and data analysis. Organising the data using a star schema optimises data access by simplifying business reporting queries. Queries are simplified because the number of joins between tables are reduced resulting in performance gains over similar queries in a relational model.
Example basic star schema:
At TAP CXM we like to explore a holistic approach to the use of data models in accordance with the outcomes each client or project requires.
The initial approach is to decide on which model is appropriate as the framework in relation to the existing data landscape and project use cases, before moving forward with design.
It’s not uncommon for the anticipated data model type to change in the early stages of a project as more details about the source systems, existing data and use cases become available.
Read more about Tableau and Bi here

